FORCIA Meetup #4 PostgreSQL vs Elasticsearch -ファセットカウント編-
こんにちは、広報の伊藤です。
本日はエンジニアがテーマに沿ってLT(ライトニングトーク: 10分程度の発表)を行うイベント「FORCIA Meetup」の内容をお届けいたします。
FORCIA Meetup #4 高速検索を支えるPostgreSQLのノウハウ
2月15日開催のLTのテーマは「高速検索を支えるPostgreSQLのノウハウ」
フォルシアでは、独自の技術基盤Spook®の開発にPostgreSQLを採用しています。Spook®はデータを様々な軸で高速に検索するための技術基盤です。(参考:フォルシアサイト テクノロジーページ)フォルシアは膨大で複雑なデータを持ったお客様にSpook®を提供しており、「独自の検索最適化技術」と「これまで培ってきたノウハウ」を駆使して高速なDB検索をすることがフォルシアエンジニアの仕事の一つとなっています。
そんなフォルシアから、PostgreSQLにまつわるトピックを4人のエンジニアが語ります。
イベントの詳細はこちらをご覧ください。
本記事では「PostgreSQL vs Elasticsearch -ファセットカウント編-」についてご紹介します。イベントの雰囲気が少しでも伝わればと思いますので、ここから先は書き起こしスタイルにてお届けいたします。
PostgreSQL vs Elasticsearch -ファセットカウント編-
力石(司会):では4人目の方のLTに移りたいと思います。最後になりますが、籏野さんで、「PostgreSQL vs Elasticsearch -ファセットカウント編-」ということで、すごい面白いタイトルですね。はい、籏野さんよろしくお願いいたします。
籏野:はい、では籏野から発表させていただきます。音声大丈夫そうでしょうか?ありがとうございます。では、私の方からは「PostgreSQL vs Elasticsearch -ファセットカウント編-」ということで、発表させていただきたいと思います。よろしくお願いします。
まずは簡単な自己紹介なんですけども、私、籏野拓(はたの・たく)と言います。新卒でフォルシアに入りまして今4年目となっています。ソフトウェアエンジニアをやってるんですが主に福利厚生系のアプリを中心に保守・運用・開発をやったりとか、最近だと自社プロダクトの方もちらほら開発に携わったりしております。
主に業務の中で使っているところとしてはWebアプリケーションとしてはTypeScript、Node.js、React、Next.js、PostgreSQLなどなど触ったりしています。またWebアプリ関連だけではなくてインフラ関連というところでAnsibleを使ってサーバー構築やったりとか、実際サーバー作ってAWS使ったりとか、k8sで環境を作ったり、Dockerで実際開発をやってみたりとかっていうところで、触ったりしております。

フォルシアの検索
ちょっと繰り返しな感じになってしまうんですが最初にちょっとフォルシアの検索というところで簡単に紹介したいと思います。
フォルシアの検索がすなわちSpook®というとこになるんですけども、Spook®がフォルシアで使っている各企業が独自に持つ膨大で複雑なデータを最適に検索をするための技術基盤というところになっています。このSpook®を使うとどういう検索に対して主に強みを発揮するのかというところでいくと、主に旅行会社とかをイメージしていただくとわかりやすいんですが、旅行会社とかだと、例えば都道府県であったり日付であったり、こだわり条件だったりというような、様々な属性を軸として、絞り込みを行うっていうところが多いサイト、Webアプリケーションになっています。
で、Spook®はそういったいろいろな一つの検索対象に対して様々な属性が付与されているようなデータに対して、属性によって絞り込みを行っていくっていうところに主に大きな強みを持っているものになっています。で、それを実現するために、PostgreSQLを使って独自関数...C言語を使った独自関数を作ったりして、より高速な検索を実現をしております。
今言ったように主に得意としているところは属性を軸とした絞り込みなんですけども、近年、いろんなお客様とお話とかをしている中でキーワード検索への需要の高まりっていうところも大きく感じているところです。
もちろん属性での検索っていうところもあったりはするんですが、なんですかねなんか音声検索とかそういうのが増えてきた影響なのか、いわゆる自然言語を使った自然な検索というところが増えてきているんじゃないかなと思っています。揺らぎに対応したりだとか、関連語で関連したワードで検索をかけたいとかっていうところも需要の高まりを感じておりまして、最近はそれを受けて、キーワード検索といえばElasticsearchっていうような何か風潮があるのかなという気がしているんですが、そちらの利用を検討したりしています。
PostgreSQL vs Elasticsearch
ということで本日はそんな検索エンジンElasticsearchとPostgreSQLというところを比べていきたいなというふうに思っています。
まずはキーワード検索っていうところなんですが、こちらは実はFORCIA CUBEという弊社がやっているブログなんですけども、そちらの方で既に記事が出ているのでここでは簡単な紹介に留めたいと思います。
まとめると、結構雑なまとめ方ではあるんですが、普通はElasticsearchの方が5倍速いというようなところが出たりしています。そこら辺はブログの方を見ていただければと思うんですが、主な違いとしては、PostgreSQLの場合だとC言語による拡張機能が書けますと。
一方、Elasticsearchの方にも同じように拡張機能というとこはあったりするんですが、そちらはJavaで書けたりします。なので、なんかC言語とかっていうとよりシステムの深いところまで理解が必要なのかなというようなイメージがあるんですが、よりシステム開発者向けな拡張機能というふうになってるのかなというふうに思っています。
キーワード検索というところでいくとElasticsearchの場合そのキーワード検索に必要な機能っていうのは、ワンストップでもう最初っから備わってることが多いです。形態素解析であったり、揺らぎの対応であったりっていうところの拡張機能を使えばかなり簡単に対応ができるかなというふうに思います。
PostgreSQLでも似たような形態素解析器、MeCabであったりというところをPostgreSQLから呼ぶっていうところも一応出来はするんですが、基本的に自作する必要があるというところでキーワード検索に関して言えば、デフォルトの状態を見ればElasticsearchの方に軍配が上がるのかなというふうに思います。

ただし、先ほど言っていた属性を使った絞り込みというところでいくと、一つ大きな特徴として、ファセットカウントと呼ばれるものがあります。ファセットカウントって何なのかなっていうと、旅行会社の検索ページとか見ていると皆さん目にしたこともあるんじゃないかなと思うんですが、いろいろなこだわり条件がある中で、そのこだわり条件を選んだときに何件になるのかっていうところが事前にわかるっていう機能になります。
こちらはフォルシアが扱っているサイトでもたくさん出てくるところではあるんですが、キーワード検索は、Elasticsearchの方に分配軍配が上がりましたが、ファセットカウントを出すところで見てみるとどっちの方が早いのかなっていうのを今回速度比較をしてみました。

ファセットカウントの速度比較
はい。実際にどんなことやったのかなっていうとこを紹介したいと思います。
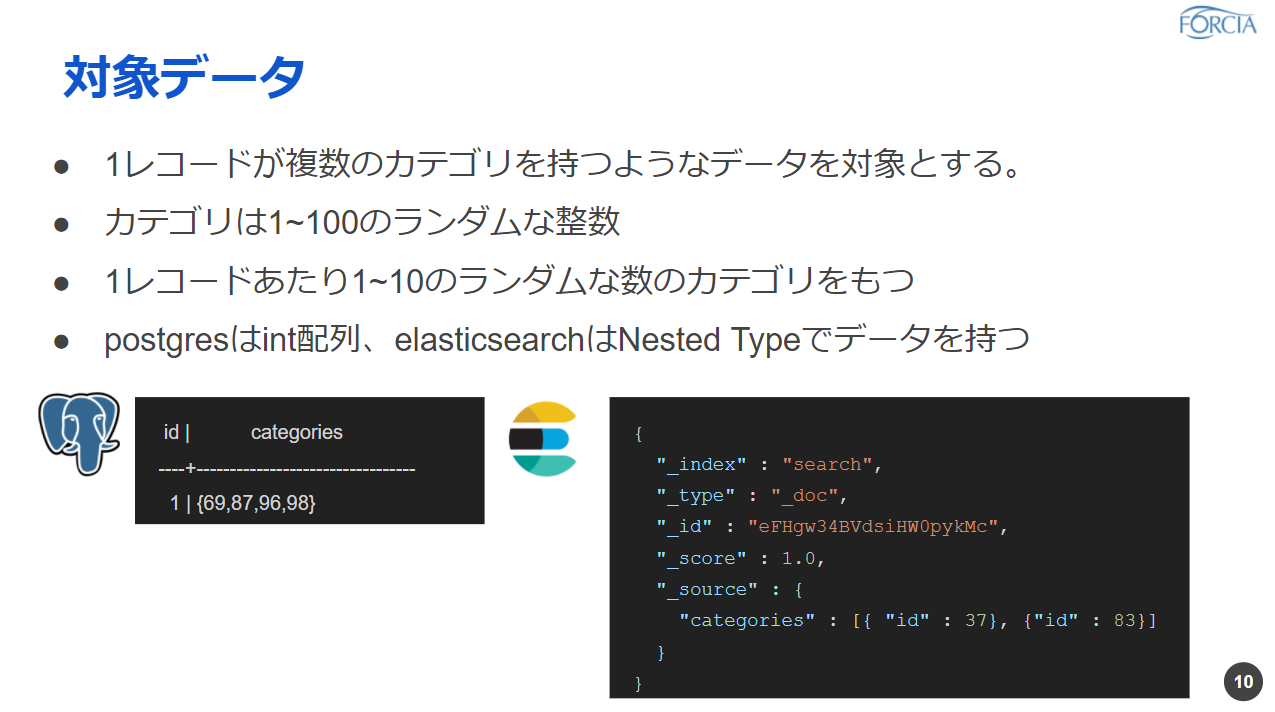
今回対象とするデータとしては1レコードあたりに複数のカテゴリを持つと想定しているデータになります。カテゴリっていうのは何なのかっていうとこでは今回は1から100のランダムな整数というふうにしてみました。1レコードあたり1個から10個までのランダムな数のカテゴリを持つというような形にしています。1つのレコードで複数のカテゴリを持つということで、PostgreSQLの場合はint配列、ElasticsearchはNested Typeって型があるんですけどもそちらを使ってデータを持つようにしてみました。
実際にクエリ投げて1レコードを見てみると、こちらの画像にあるようになっております。
実際これ集計どうやってやるのかなっていうのを考えてみると一番簡単なクエリを考えてみました。PostgreSQLの場合はさっきの話でもちょっとありましたが配列の操作っていうところだとちょっと組み込み関数とかっていうところでは厳しいというところもあるので、一旦カテゴリをunnest、要するにレコードに直してからカウントするというようなことを考えてみました。
一方、Elasticsearchの方はSQLではなくてこういうElasticsearch独自の文法、まぁJSONではあるんですが、JSONを使って絞り込みを行うようになっています。この場合だとAggregationsっていう機能があるんですけども、そちらを使って、先のデータにあったCategoriesの中のIDっていうデータを対象にして、そちらを集約してカウントするというような形になっています。

計測方法
この2つを使って今回速度検証してみました。
具体的な計測方法なんですが、ある一つの操作を、一連の操作を10回繰り返して、その実行時間の平均を取るという形で速度を比較していました。
今回対象とするデータとしては、1万、10万、100万という3つのデータを、ランダムなデータを生成してそれに対して、クエリを投げるという形で実行していました。参考までなんですが、フォルシアで扱っているあるアプリ見てみると、施設数が3万件、プラン数120万件というようなアプリがあったのでその辺のオーダーも意識して今回速度比較というところをやってみました。
計測結果
もう早速の計測結果を言ってしまうんですが、検査結果はこのような形になりました。
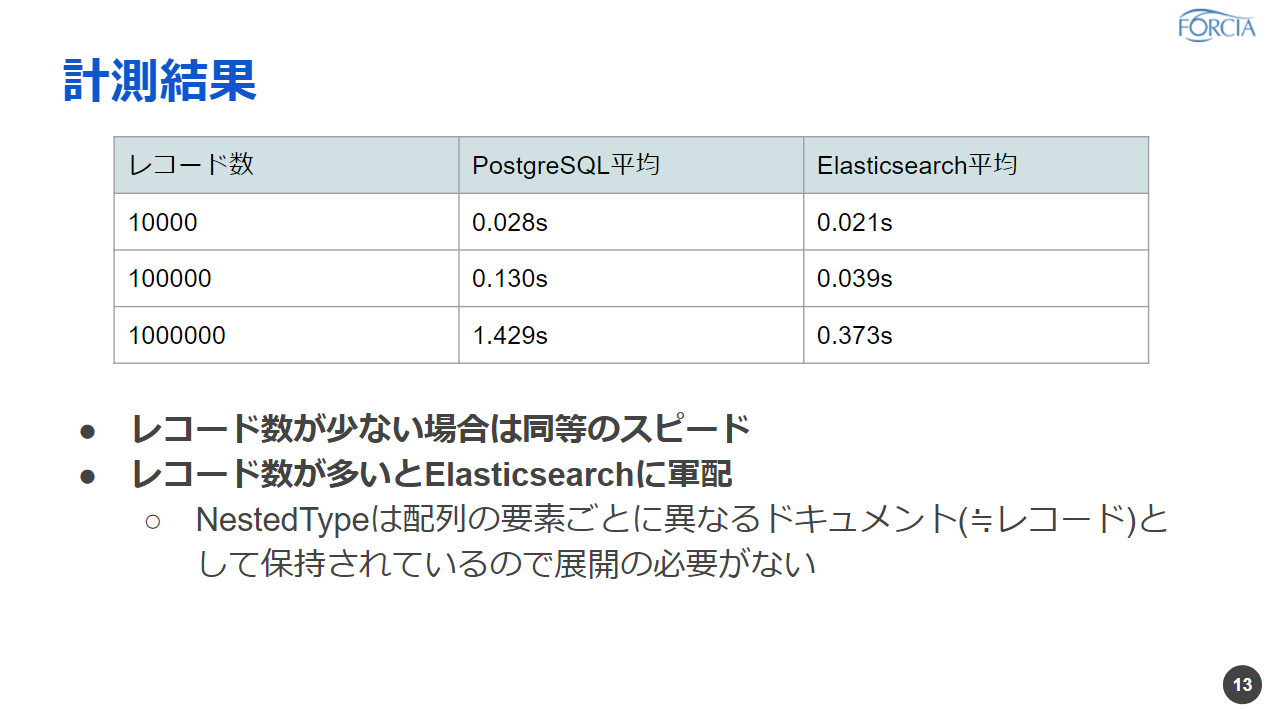
上から1万件、10万件、100万件という形になっています。こちらぱっと見てもわかる通り、レコード数が少ない場合、1万件ぐらいの場合だとPostgreSQLとElasticsearch、そんなに差はないのかなというような印象になっています。
ただレコード数がどんどん増えてくるとその差が開いてきて、最終的に100万件で比べてみるとPostgreSQL:1.4秒、Elasticsearch:0.37秒ということで4倍近い差が出ているのかなというふうに思ってます。
ということで、ファセットカウントと今回のような集約してカウントするようなところを比べてみると、レコード数が多い場合にはElasticsearchに軍配が上がるのかなというふうな結果が出てきました。これ何でなのかなっていうのを簡単に考えてはみたんですが、ちょっとElasticsearch初心者というところもあるので、もしかしたら間違っているところもあるかもしれないんですが、今回は実際に持っているデータの型、データの持ち方っていうところに注目してみました。
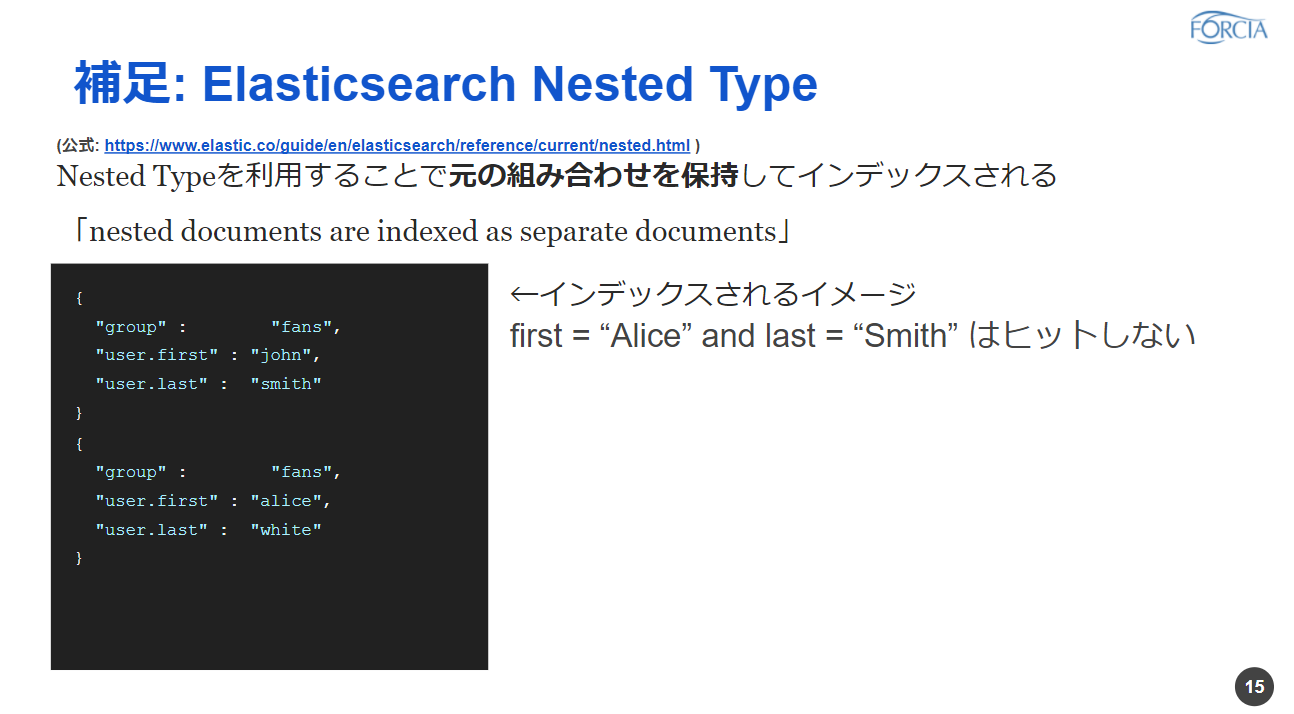
さっきのお話でElasticsearchの場合はNested Typeというような型でデータを持つというようなことを言ったんですが、これを使っていると、これを使っていることが一つ、速度が速いというとこに繋がってるんじゃないかなというふうに思ってます。
Nested Typeっていう型の前にElasticsearchでオブジェクトの配列を持ったときにどういう挙動をするのかなっていうところを簡単にご紹介したいと思います。
Elasticsearchで単純なオブジェクトの配列を持っている場合、例えば今回の例ですと、ユーザーっていうカラムに対して姓名...名前を一つグルーピングして持っているというようなデータを考えています。そうすると普通はジョン・スミスさんとアリス・ホワイトさんと2つのレコードがあるんですが、これは単純なオブジェクトの配列で持っていると、ジョンとスミス、アリスとホワイトっていう組み合わせが保持されない形で、Elasticsearchの場合はもってしまうということがあります。このため、例えば名前がアリス、姓がスミスというふうに絞り込んだときに実際はアリス・スミスさんという人はいないのに実際絞り込めてしまうというようなところがあったりします。
これを制御するかどうかっていうのは検索の要件であったりとかによると思うんですが、こういう挙動があったりします。

一方のNested Typeっていうものを利用すると、先ほどとは違って、元の組み合わせを保持してインデックスされることになります。なのでちょっと実際に中身を見たというよりはイメージではあるんですが、このような形で一つ一つ組み合わせを保持した形でバラバラにして保持されるのかなというふうに思っています。なので、つまり、配列では持っているんですがそれがあらかじめ展開された状態でもってるような形になるのかなと思ってます。なので、PostgreSQLの場合はいちいちintの配列を展開してから集約するというような流れになるので、その分、Elasticsearchの方が素早く、集約して、計測・カウントすることができるのかなというふうに思いました。
Spook®でも計測を行ってみた
じゃあファセットカウント、PostgreSQLだと勝てないのかというと、どうなのかっていうところを最後にご紹介したいと思います。
先に言いましたSpook®の場合はPostgreSQLを使って独自の関数を、関数であったりとか型っていうところを作ったりしてデータを保持しています。それを使って全く同じデータに対して検索を行ってみるとこのような形になりました。
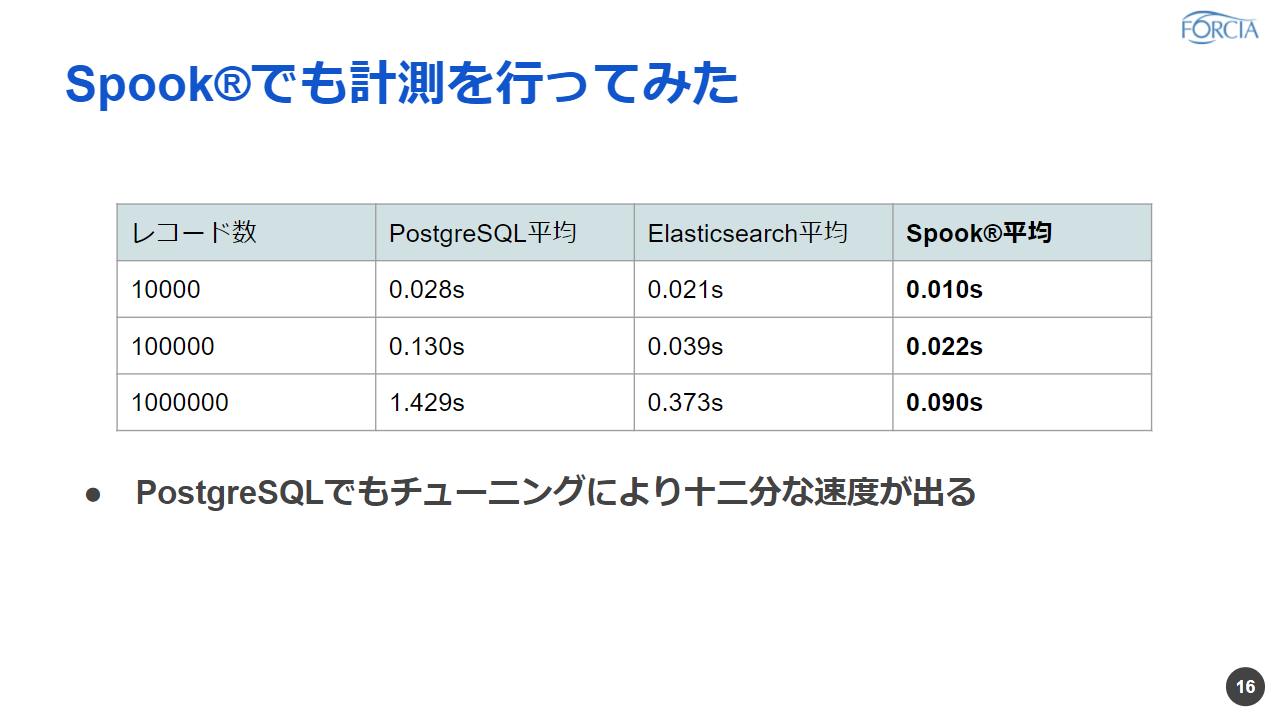
はい、こうやってみるとPostgreSQLの場合でも、レコード数が少ない場合でも多い場合でも、十二分な速度が出るというところがおわかりいただけるかなと思います。
なのでPostgreSQLでもチューニングにより十二分な速度が出るんですが、実際の検索の要件であったりでどっちを使うのかっていうのは今後さらに検討していきたいなというふうに思っております。
まとめ
はい、ということでまとめです。ElasticsearchのAggregationという機能を使うことで先ほど見ていたようなGROUP BY相当の集計ができるということがわかりました。Elasticsearchの場合チューニングしなくても単純にNested Typeで持ってあげれば、ある程度の速度が出るんだなというところもわかりました。ですが、PostgreSQLの場合独自で様々な関数型っていうのを作ることができるので、それを使うことで十分な速度を出すこともできるというところになっております。というところで私の発表は以上になります。ご清聴ありがとうございました。
LTを終えて
力石(司会):籏野さんありがとうございました。はい、ということで皆さま質問の方、Meetのチャット欄やTwitterの「#forciameetup」のハッシュタグでどしどしお待ちしております。私からそうですね...全然Elasticsearchを使ったことがないので、なんかすごい速いぐらいしか知らなかったのですが、すごい...かなり速いですね。Elasticsearchは何で実装されているんでしょうか?
籏野:Elasticsearch自体は何でしたっけね...。Apache Luceneを元にしていたと思います。
力石(司会):なるほど。Apache Luceneなるものが使われてるんですね。
籏野:まぁ同じ組込みでいけばApache Solrとかも確か同じように拡張して使ってたんじゃないかなというところで、キーワード検索とかだとよく使われているものになるんじゃないかなと思います。
力石(司会):なるほど。ありがとうございます。Twitterの方では、「チューニングのパワー」ときております。そうですねこれ、やっぱりチューニングで実際Elasticsearchの100万件のレコードでElasticsearchの4分の1ぐらいまでなるっていうのはすごい...すごいとしか言えないんですけど(笑)
籏野:そうですね。ちょっと自分も実装したものではないのでやはりこれまでの作ってきた英知というか、知見というのが集結すると、極めるとここまで速くなるんだなっていうのは自分も今回の検証で実感はできたので、そういった意味で、非常にいい検証だったなというふうに思います。
力石(司会):はい、すごい定量的で見やすくてわかりやすかったです。それでは籏野さん、ありがとうございました。
籏野:ありがとうございました。
FORCIA Meetup #4 書き起こし記事、お楽しみいただけましたでしょうか
いかがでしたでしょうか。速さにこだわりをもつフォルシアならではのLTだったかと思います。アドベントカレンダー2020、FORCIA Meetup#4に続き第3弾はあるのか?!こうご期待!
さて、これにて全3回にわたってお届けしておりますFORCIA Meetup#4の書き起こし記事も終幕となります。記事を読んでくださった皆さま、ありがとうございます!フォルシアではこれからもフォルシアのエンジニア、技術が伝わるイベントを開催していきます。是非次回はイベントへのご参加もよろしくお願いいたします!
伊藤 明日香
2021年6月キャリア入社/経営企画室 広報
あたたかくなるのは嬉しい反面、花粉と戦う春です
フォルシアではフォルシアに興味をお持ちいただけた方に、社員との面談のご案内をしています。
採用応募の方、まずはカジュアルにお話をしてみたいという方は、お気軽に下記よりご連絡ください。
※ 弊社社員に対する営業行為などはお断りしております。ご希望に沿えない場合がございますので予めご了承ください。