フォルシア技術研究所(技研)の原です。
技研では、新しいサービスの創出、および既存のサービスの拡張や効率化に資するべく、今までのフォルシアでは使われていなかった技術の開発、導入を進めています。
その一つが、商用アプリへの社内初の Kubernetes の導入です。この記事では、フォルシアでの Kubernetes の利用、工夫、苦労したところなどを紹介したいと思います。
(その他、技研ではRust によるインメモリDBの開発なども行っており、Rust については、Software Design 6月号(技術評論社)に「入門! Rust」という特集記事に私と技研の松本が執筆させていただいたり、実践Rustプログラミング入門(秀和システム)をフォルシアで監修させていただいたり、執筆に松本が参加させていただいたりしております)
Kubernetes とは?
Kubernetes はコンテナオーケストレーションシステムと呼ばれるものです。オーケストレーションって何ぞや?と言いたくなるかもしれませんが、たくさんのコンテナを効率よく管理するためのツールであり、Kubernetes を使うと以下のようなメリットがあります。
- 同じコンテナを複数実行することで、簡単にレプリカを作って、レプリカ間でロードバランスをすることができる
- 複数のワークノード(物理マシンやVM)でクラスタを構成し、ワークノードの存在をほとんど意識せずに、インフラを利用することができる
- 必要なリソース(CPU、メモリ)に応じて、自動的にワークノードを増やしたり減らしたりできる(自動なので、これもユーザーがその増減を意識することはない)
サービスの規模に応じてインフラを柔軟に増減させることができるので、フォルシアでもサービス展開が進んでいる SaaS 型のサービスと非常に相性がよく、SaaS型サービスを展開していく上で、基盤となり得るものです。
Kubernetes + ecflow でワークフローを実行する
Kubernetes は宣言的
フォルシアのアプリを Kubernetes 上で稼働させる上で必要なことの一つに、「バッチ処理が終わったあとにバッチで加工されたデータを使ってアプリ(Pod)を起動(deploy)する」というフロー処理があります。
Pod というのは、Kubernetes でのワークロードリソースの最小単位で、各Pod では1つまたは複数のコンテナが実行され、Pod 内のコンテナではネットワークやボリュームを共有しています。Pod にアプリのコンテナなどを搭載して、サービスを提供します。
Kubernetes のアーキテクチャは「宣言的である」とよく言われます。ユーザーは、Kubernetes に「希望する状態」(たとえば、レプリカを3つ作ってほしい、docker イメージを更新したアプリ(Pod)に取り替えてほしい、など)を宣言します。その「希望」はYAML または JSON で記述された「マニフェスト」と呼ばれるもので表現して、kubectl apply というコマンドでKubernetes に入力します(kubectl は Kubernetes の API サーバーとやりとりをしており、kubectl を使わずに直接APIサーバーと通信することも可能 )。
その宣言を受けて、Kubernetes は現状のKubernetes クラスタの状態と入力された宣言との違いを察知し、その差をなくすようなアクションを行います(たとえば、レプリカ数が足りなければ、希望するレプリカ数になるように Pod を追加で作成する、など)。
宣言した状態になった?
このようにして、Kubernetes はKubernetes クラスタの状態をユーザーが宣言した状態に近づけ、最終的には宣言した状態と差がないようにしてくれますが、フロー処理を実行するためには「宣言した状態になった」ということを検知して、それをトリガーに後続の処理を実行するということが必要になります。
たとえば、Kubernetes の Jobリソースと呼ばれるものを用いてバッチジョブを起動して、そのバッチジョブの終了をトリガーにして新しい Deployment リソースを作成してPod を deploy する場合などです(図1)。
「指定したジョブを実行して完了させる」という状態を宣言した Job リソースを作成すると、バッチジョブのPodが作成されてジョブの実行を開始し「ジョブを完了させる」という「宣言した状態」に近づけます。この操作の中で、 「Jobリソースの作成」(kubectl apply で実行)は宣言を入力しているだけで、kubectl applyはその宣言が受け付けれられると終了しますので、その後、宣言した状態が実現したのか、またはエラーが発生したのか、などは別途ユーザーが検知をする必要があります。
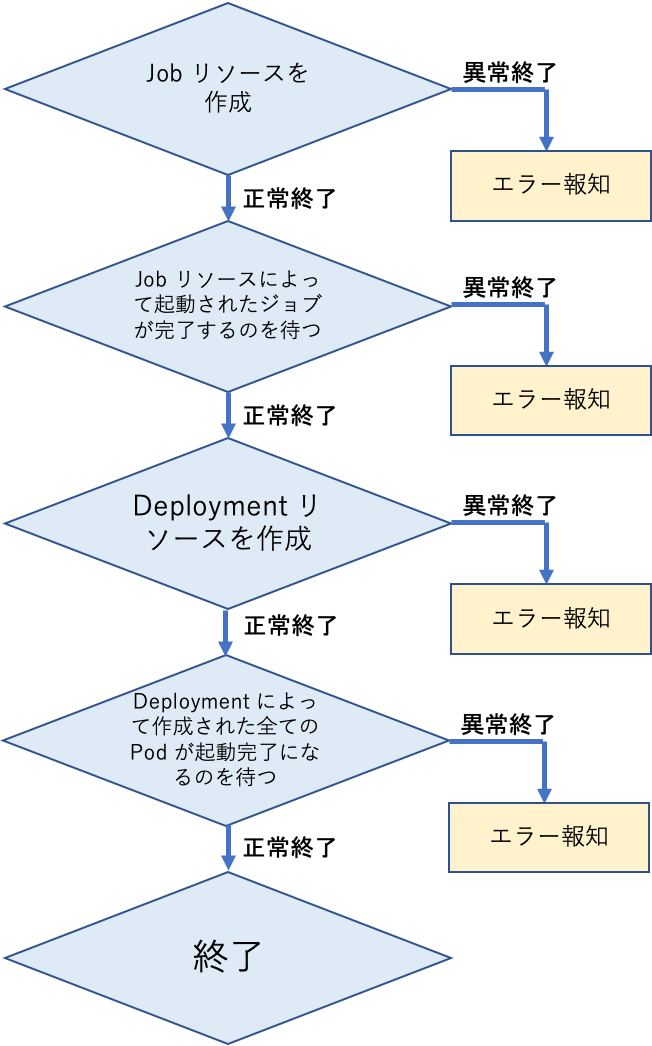
図1: Kubernetes のリソースの作成と、宣言された状態になるまで待つフローの一例
宣言した状態になったことを検知
Pod のリソースの状態を問い合わせる kubectl get pod には --wait というオプションがあり、ある状態になるまで kubectl が終了するのを待つというオプションが実装されてはいますが、まだ実験的(experimental)な オプションであり、エラーの検知やエラーハンドリングを柔軟に行えるようにするため、--wait オプションを用いず、リソースの状態をAPIサーバーにポーリングしています。ただし、「ポーリング」といっても一定時間間隔でリクエストを送信するのではなく、watch オプションを用いて、リソースの状態の変化があったときにそのリソースの内容を受け取ることができるようにして、APIサーバーへのリクエストの負荷を小さくしています(AWS の SQS のロングポーリングに似ています)。
API サーバーを通じてPodの状態を取得していますが(kubectl get pod -o yaml --wait に対応)、リソースの状態にはエラーの場合を含め、いろいろなパターンがあることがわかりました。そのパターンを網羅し、読み取ったPodのリソース状況をトリガーに、エラーハンドリングも含めて適切な処理ができるようなモジュールを開発しました。このモジュールによって、バッチ処理が終了したり、Pod がすべて正常に起動したなどの"イベント"を検知して、次の Kubernetes リソースの適用などのフロー処理をしています。
(これらの処理は、Kuberenetes Operator を実装できれば、Kuberenetes に閉じた世界で実現出来そうですが、そのハードルは高いので、今回はリソースの状態問い合わせを行う外部モジュールを開発して対応しました。)
フロー処理には ecflow を活用
世の中には様々なワークフローエンジンがあります。その中で、Apache airflow が有名なものの一つです。私も使ってみたのですが、airflow は時間がかかるETL 処理を扱うことが前提になっており、前のタスクが完了して次のタスクが投入されるまでに数十秒以上の時間がかかります。それぞれのタスクの実行時間が短い場合には、タスクとタスクの間の数十秒という時間が大きなオーバーヘッドになってしまいます。
そこで、欧州中期予報センター(ECMWF)が自らのスーパーコンピュータでのプログラム実行のために開発した ecflow というワークフローエンジンを用いています。ECMWF が開発している天気予報のためのスパコン用のプログラム(数値予報モデル)は世界一の精度を誇り、ecflow は複雑な依存関係を持った大量のタスクから天気予報のためのプログラム実行の運用を担っています。ecflow は apache 2.0 ライセンスで配布されており、天気予報以外のワークフローにも用いることができます(ecflow については、FORCIA Meetup #1 〜DevOpsやっていかnight〜でも紹介しました)。
kubectl apply で新規のリソースを作成したり、既存のリソースを更新して、ポーリングによって「宣言した状態になった」(またはその仮定でエラーが生じた)ということを検知する一連の処理を一つのタスクとして、前のタスクが「宣言した状態になった」のを検知して次のタスクを投入する、という処理を ecflow でやっています。
マニフェストのテンプレート化
「宣言した状態」を記述したものをマニフェストといい、JSON または YAML で記述しています。ecflow の中で kubectl apply で適用するマニフェストは Mako Templates for python によってテンプレート化して、テンプレートに与える変数を ecflow から与えています。Kubernetes マニフェストのテンプレート化には、Helm や kuscomize などのツールがありますが、他の社内ツールでも使い慣れたもので直感的にテンプレート化したいと考え、社内でも利用実績がある Mako によるテンプレートを選択しました。
Kubernetes は SaaS 型のサービスとの相性がよいですが、マニフェストをテンプレート化をすることで、複数のサービス提供先にも同じテンプレートで対応することができて、実装がすばやくできるようになり、また保守性が非常によくなりました。
フォルシアのプラットフォームへのKubernetes の導入
これまでも、大量のログを扱うログ基盤(HDFSやSpark)に Kubernetes をオンプレミスで導入していましたが、上で紹介した技術を用いてGoogle Hotel Ads のサービスを提供するアプリに Kubernetes を導入しました。そして、そのノウハウをほぼそのまま、フォルシア web コネクトにも適用して、9月1日よりサービス提供をしています。
AWS EKS の利用
Kuberenetes を利用するにあたり、クラウドのマネージドシステムを利用して、Kubernetes で実行するアプリなどの開発に集中できるようにしました。
クラウドのマネージドシステムとして提供されている Kubernetes には、AWS の EKS、GCP の GKE、Azure の AKS などがあります。GKE なども試用してみましたが、フォルシアではAWSの利用が最近活発になっており、これまでの経験による"土地勘"があることを重視して、AWS EKS を選択しました。
これまで、ログ基盤でオンプレのKubernetes を構築した経験がありましたが、マネージドシステムの Kuberenetes は簡単にクラスタを構築でき、オンプレのこれまで利用してきた Kubernetes とほぼ同じように使えており、マネージドシステム特有の制約は特に問題になることなく利用できています。
ingress を実現するALBの target-typeに注意
EKS の ingress は ALB で実現
EKS では ingress のリソースを deploy すると、Application Load Balancer (ALB) が構築され、ingress の機能を実現します。ALB を ingress として使う場合には、リクエストを受けるポートを NodePort として公開するService リソースを適用することが必要です。
その結果、たとえば、ワークノードが2つあり(AとB)、NodePort が 30001 の場合、ワークノードAまたはBの 30001 ポートにクラスタ外部から接続すると、サービスを提供しているPodのいずれかにリクエストが転送されます。ワークノードAでPodがサービスを提供していて、ワークノードBの 30001 ポートに接続すると、その接続はワークノードBからワークノードAに転送されることになります。
デフォルトは target-type=instance
EC2でwebアプリを構築している場合、ALB ではリクエストを振り分ける先であるターゲットグループをインスタンス(EC2のインスタンスID)で指定すること(target-type=instance)が一般的かと思います。
EKS の場合もこれがデフォルトになっており、Kubernetes に deploy されている ALB コントローラが、クラスタのワークノードをALBのターゲットグループに登録してくれます。ALB は登録されたワークノードのいずれかのNodePortにリクエストを振り分け、その NodePort からさらにService のエンドポイントになっているいずれかのPodにリクエストが割り振られることになります。
時々、ALBから504エラーが
この状態でサービスにデッドタイムが生じないかを調べるテストをしていたところ、時々、ALBが 504 (Gateway Timeout) のエラーを出しました。エラーとなるタイミングを調べてみると、クラスタオートスケーリングによってワークノードが削除される(スケールイン)ときにエラーになる場合があることがわかりました。
ALB はNodePortを通じて登録されているワークノードのいずれかにリクエストを振り分けますが(図2)、その登録はワークノードが削除されるタイミングで解除されます。
しかし、スケールインの場合には、ワークノードが削除される前にそのノードで実行されていた Pod は削除されてリクエストを受け付けなくなります(削除されたPodは別のワークノードに deploy されます)。
つまり、リクエストを受ける Pod はないが、ワークノードはまだ存在しているという場合が生じます(図3)。その結果、ワークノードが存在しているので ALB がリクエストをそのノードに振り分けるものの、リクエストを受け付けるポートがないという状況が発生して、そのためタイムアウトになっていた、と推定しています。
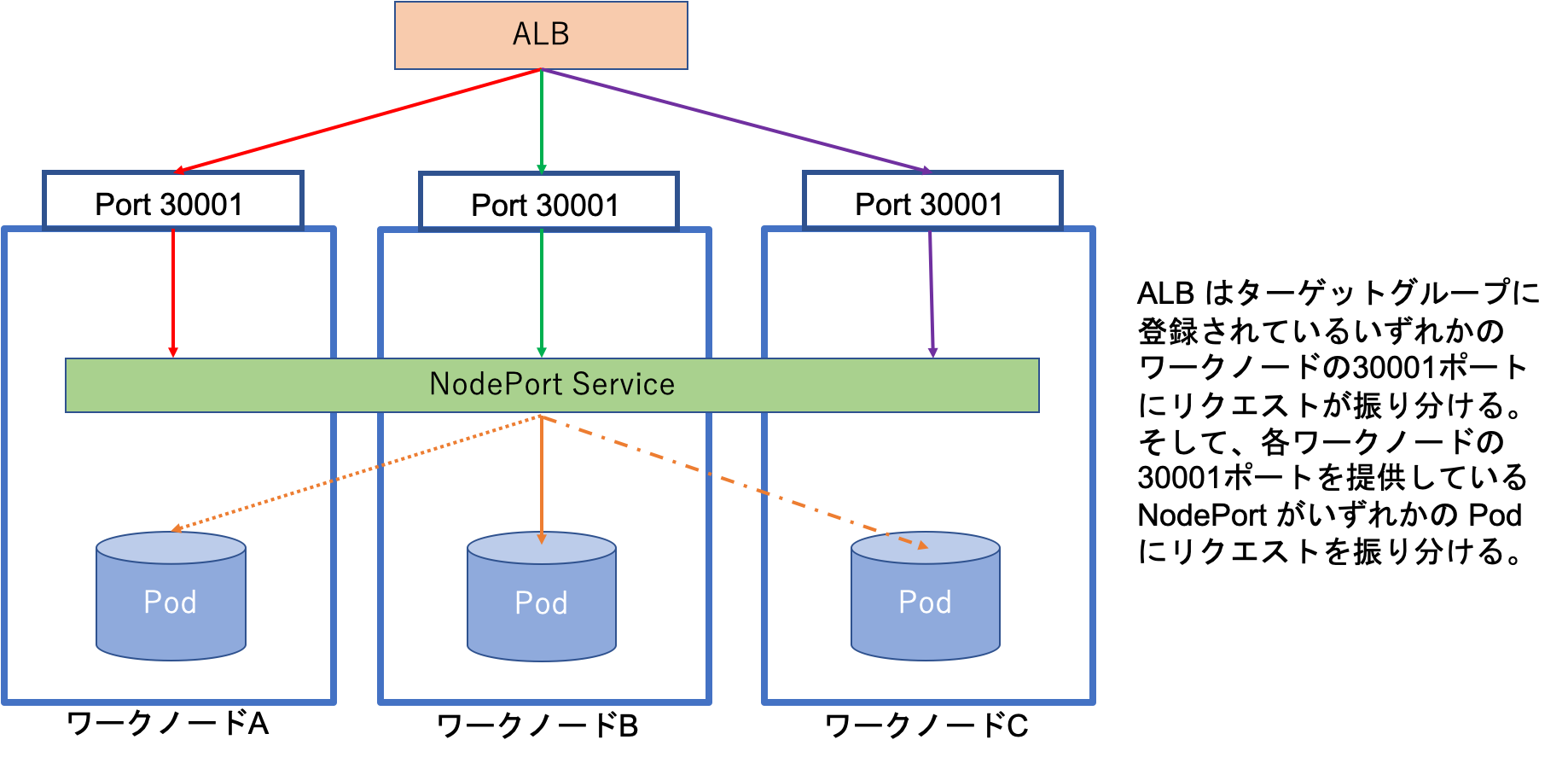
図2: ALBからのリクエストの流れ(target-type=instance の場合)
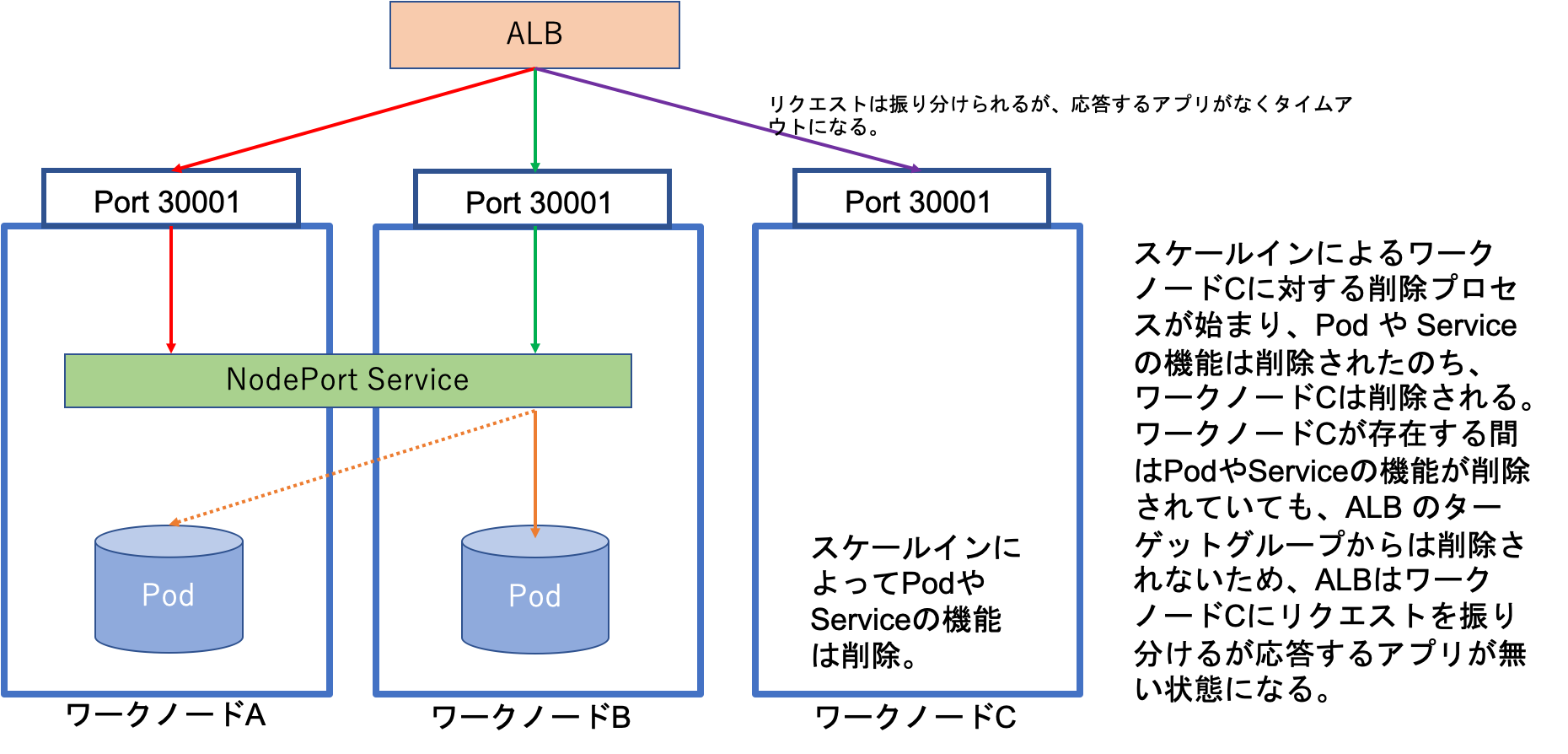
図3: ワークノードの削除プロセス中の状態(target-type=instance の場合)
target-type=ip にすることで解決
この状況に困っていたのですが、ALB のtarget-type のもう一つのモードである ip に切り替えること(ingress の annotation で指定する)で解決しました。
target-type = ip の場合、ALBコントローラによってPod の IPアドレスをターゲットグループに登録されます(図4)。そして、Pod が削除されると即座にALBのターゲットグループからそのIPアドレスを削除され、その Pod にはリクエストがALBから振り分けられなくなります(図5)。ワークノードがスケールインで削除される場合には、ノードが削除される前にPodが削除され、ALB のターゲットグループからもそのPod の IPアドレスが削除されるため、ALBがリクエストを振り分けたけどリクエストを受け付けてくれるPodがない、ということがほぼなくなります。
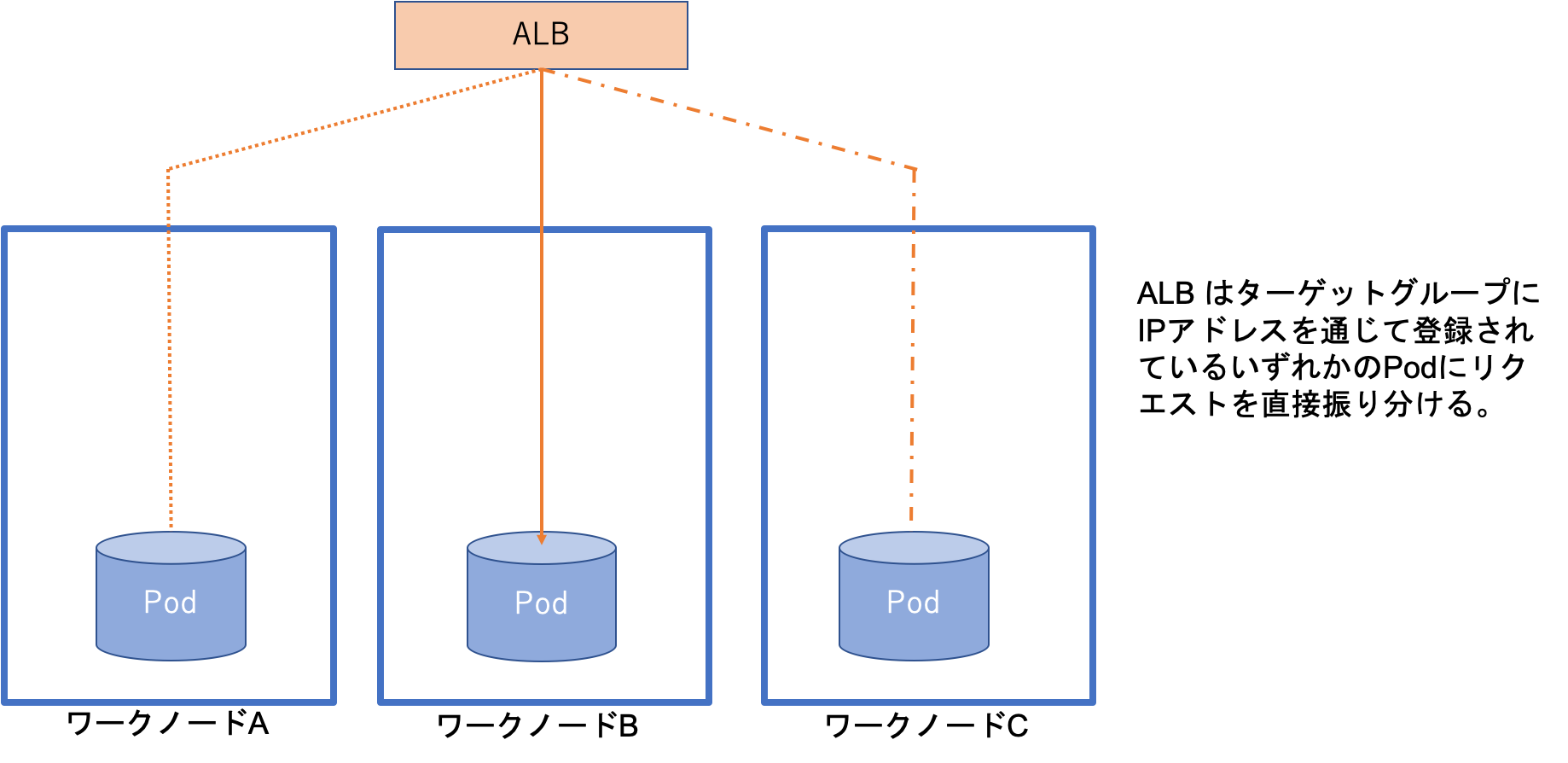
図4: ALBからのリクエストの流れ(target-type=ip の場合)
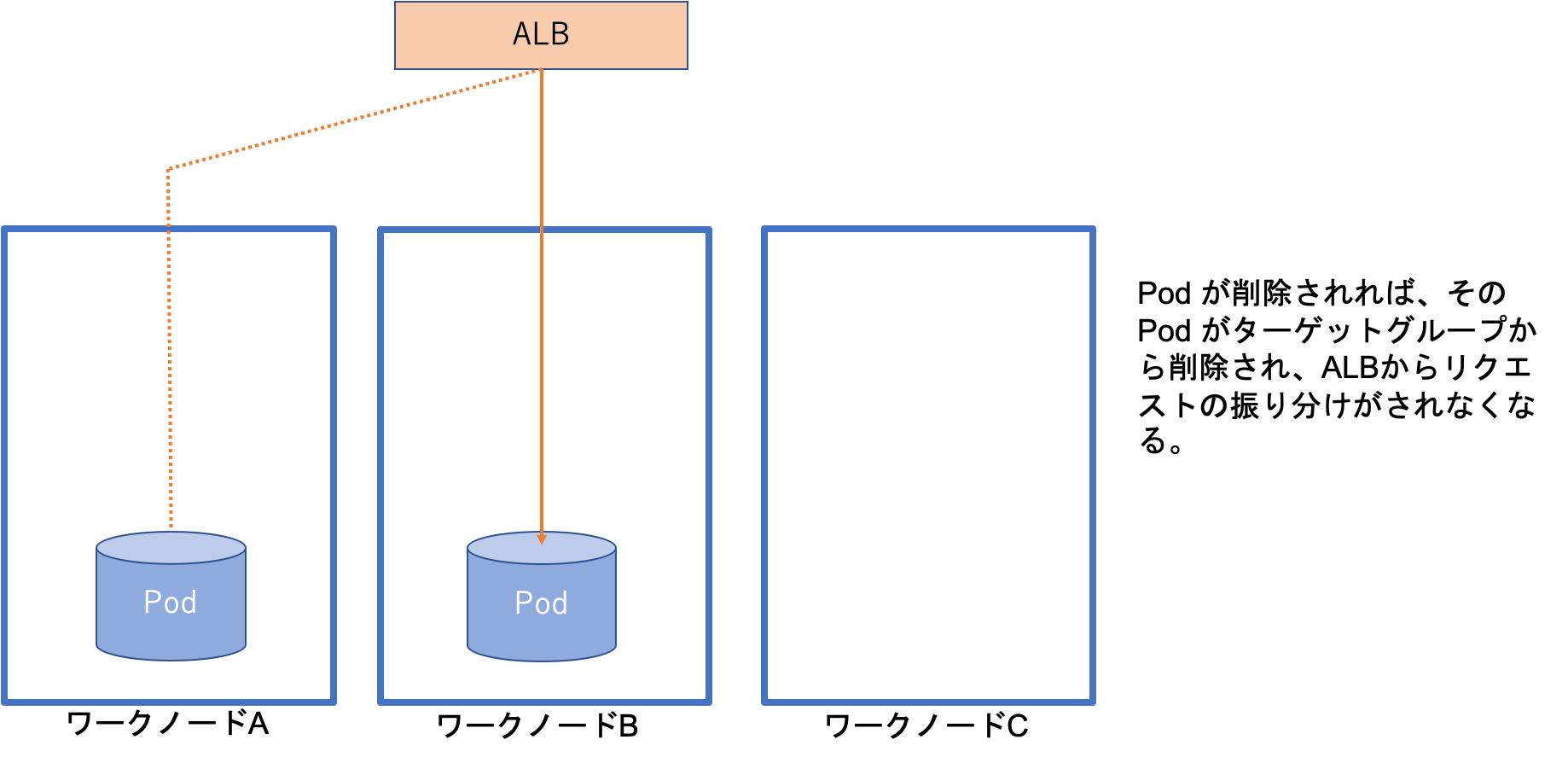
図5: ワークノードの削除プロセス中の状態(target-type=ip の場合)
さらに、target-type = ip の場合はALBとPodが直接つながっているため、Pod が削除されるプロセスの中で、Pod からALBのヘルスチェックに対して unhealthy のシグナルを送り、Pod が削除される前にALBからリクエストが割り振られないようにすることができます。
それによって、Pod が削除されるタイミングとターゲットグループからの削除のタイミングの微妙なタイムラグによって、ターゲットグループに存在している間にALBがリクエストを振り分けたけどPodはすでにない、という場合が起こらないようにして、504 エラーが発生することを回避しています。
また、target-type = instance の場合には、ALB から NodePort を経由して Pod にリクエストが送信されていましたが、target-type = ip の場合は、ALB から直接 Pod にリクエストが送信されるので、オーバーヘッドが少なくなると思われます。
EKS で ingress を使う場合には、target-type = ip にすることを忘れないようにしましょう。
CKA, CKADに認定
Linux Foundation では、Kubernetes管理者の責任を果たすためのスキル、知識、および能力をが備わっていること認定するCertified Kubernetes Administrator (CKA) 試験、Kubernetes用のクラウドネイティブアプリケーションを設計、構築、構成、公開できる能力が備わっていることを認定するCertified Kubernetes Application Developer(CKAD)試験を実施しています(詳しくは Linux Foundationのページ)。
いずれも、ハンズオン形式での試験で、実際のKubernetes クラスタを操作して、クラスタを試験問題が要求する状態にします(Kubernetes が宣言的であるからこそ、可能な試験形態と言えます)。
私は、Kubernetes の社内初の商用化の後に、自分のスキルの確認や知識の整理のためにCKA および CKAD を受験し、ともに 90%以上の得点で合格できました。実務経験で培ったものは大きく、多くは経験で対応できたものの、あやふやだった知識を再確認したり整理するためのよい機会にもなりました。
その他、AWS 認定のソリューションアーキテクトアソシエイト、ディベロッペーアソシエイト、SysOps アドミニストレータアソシエートにも合格しましたが(いわゆるアソシエイト三冠達成)、その学習の中でAWSの様々なサービスやその背景にある思想を知ることができて、Kubernetes とともに「クラウドネイティブ」に対する理解が深まりました。
まとめ
新たなものを導入するのは、技術の習得や、求められるサービスレベルに達していることを確認することなど、いろいろな障壁があります。
また、導入することへの強い必要性がないと、優先度が上がらず、いつまでもダラダラと取り組み、結局、モノにならないということも多々あります。
本件では、いつまでにKubernetes の導入の可否を判断するということを設定し、Kubernetes の導入実績を作ることは今後の技術開発やビジネス展開に大きな意義があるという信念を持って、Kubernetes や周辺技術の習得、それを踏まえたシステムの開発、ロングランテストや負荷テストを含む徹底的なテストを行い、その結果、ゴールに達することができました。
この技術をSaaSビジネスの基盤として今後も展開していくとともに、さらなる技術の研究開発に取り組んでいく所存です。
原 旅人
フォルシア技術研究所部長。物理屋(素粒子理論)出身。
日本においてスパコンで天気予報をするソフトウェア(数値予報モデル)の予報精度改善のための開発に14年間従事したのち、2018年4月にフォルシアに入社。Webアプリ開発からデータ分析案件(クラスタリング、レコメンドなど)、コンテナの商用化などを手がける。
最近の趣味は Kubernetes。Kubernetes 関連の文献を読みあさり、Go 言語を勉強しながら、Kubernetes のソースコードリーディングに励む。



