技術本部の松本です。フォルシアでは、2019年新卒の学生を対象に、ワークショップや会社説明会を実施しています。エンジニア志望者向けのワークショップでは、膨大かつ複雑なデータから高速に最適解を導く独自の「高速検索技術」を、プログラミングの実践を交えながら学べるプログラムを用意しています。

本日は特別に、4月24日(火)に青山で開催したエンジニアワークショップで出題した問題を解説します。
問題
それでは、実際に出題した問題を見ていきましょう。
問題文
N人の身長 h_iとQ個の質問クエリが与えられます。
各質問クエリは、 (h_min_j, h_max_j)の2要素で構成されます。
このとき、それぞれのクエリについて h_min_j <= h_i <= h_max_jを満たす人数を答えなさい。
※身長、クエリはすべて整数である。
入力
入力は標準入力から以下の形式で与えられる。(「←」以降は注釈です)
N Q ← このあと身長のデータがN個、次いでクエリがQ個入力される h_1 ← 1番目の身長 ︙ h_N ← N番目の身長 h_min_1 h_max_1 ← 1番目のクエリ ︙ h_min_Q h_max_Q
出力
各クエリに対して答えとなる値を整数で出力せよ。
Sample Input 0
3 1 4 9 5 3 5
Sample Output 0
2
Explanation 0
3人の身長4,9,5とクエリ(3, 5)が与えられます。身長が3以上5以下の人は1番目(4)と3番目(5)の2人です。したがってクエリ(3, 5)に対して出力すべき値は2です。
Sample Input 1
5 2 2 3 4 4 4 1 1 4 4
Sample Output 1
0 3
Explanation 1
身長が1以上1以下の人は0人です。身長が4以上4以下の人は3人です。
Sample Input 2
6 2 10 2 5 6 10 8 6 7 1 9
Sample Output 2
1 4
Explanation 2
身長が6以上7以下の人は1人です。身長が1以上9以下の人は4人です。
Level 1
上記の問題設定に具体的な制約(入力の値域)を与えて、各レベルの問題を見ていきたいと思います。まず非常に値の小さい問題を考えます。
制約(Level1)
1 <= N <= 10 1 <= Q <= 10 1 <= h_i <= 10 1 <= h_min_j <= h_max_j <= 10
この問題を解決する単純なプログラムを実装します。
- 全員の身長を配列に格納し、
- 各質問について各人の身長が範囲内に収まっているかを判定し、
- 条件に当てはまる人数を答えます。
下記がPython3の実装例です。
Python:Level1実装例
N, Q = map(int, input().split())
P = []
for i in range(N):
h = int(input())
P.append(h)
# 各質問ごとに
for i in range(Q):
h_min, h_max = map(int, input().split())
count = 0
# 各人の身長を判定する
for p in P:
if h_min <= p <= h_max:
count += 1
print(count)
上記アルゴリズムの計算量はQ回のループ(8行目)の中にN回のループ(13行目)が入っているためO(QN)になります。手元の環境で実行してみると0.1秒以下で出力が返ってきます。
Level2
制約(Level2)
1 <= N <= 10,000 = 10**4 1 <= Q <= 10,000 = 10**4 1 <= h_i <= 10,000 = 10**4 1 <= h_min_j <= h_max_j <= 10,000 = 10**4
Level2ではそれぞれの値が1000倍になります。Level1で実装したプログラムでは、答えを出すまでに約8秒の時間が必要になります。
Level1で実装したプログラムのどこに時間がかかっているかを考えましょう。2重ループによって合計Q * N回も身長の比較が行われています。 実際に自分がこの作業を行うとしたらと考えてみると、身長が明らかに範囲から外れている人には何度も質問しないでしょう。 質問ごとに各人の身長を判定するアルゴリズムは"毎回「全員」の身長を確かめる必要がある"点が非効率です。
それでは、どうすれば "「全員」に対しての判定"を避けられるかを考えてみましょう。
-
数えるのではなく、計算する。
上限以下の人数から下限に満たない人数を引くことで条件を満たす人数を計算することができます。 学校の大掃除で「12番から16番の5人は窓拭き!」のようなシーンがありませんでしたか? -
事前にソートしておく。
ソートされているというのは強い性質で、昇順にソートされていて、i番目の人が下限未満の場合、i-1番目以下の人も下限未満であることが明らかです。
これらのポイントをふまえると、問題は次のように言い換えられます。
ソートされた配列から下限未満の最後の人、上限以下の最後の人を見つけたい。
ここで、注意したい点があります。前から順番に見ていくと、探している人が配列の後ろの方にいた場合、結局ほぼすべての人の身長を確認することになります。
もっと効率良く計算するために、何人かをピックアップして質問をしたいと思います。 基本情報技術者試験を勉強している人や情報系の人なら聞いたことがあるかもしれませんが、"真ん中の人から聞いて解の存在空間を半分にする"という考え方があります。 これは"二分探索"と呼ばれる探索アルゴリズムの一つで、今回の問題設定と相性が良いため、二分探索を使ってみましょう。
二分探索を使用して「ソートされた配列からある値T以上の最初の人のインデックス」を探します。
Pを身長が昇順にソートされた配列、配列P中で身長T以上の最初の人のインデックスを探すとして説明を進めます。P[lb] < T <= P[ub](※)を満たすようにlb, ubを初期化します。この条件を保ちながら更新することが二分探索のポイントです。m = (lb+ub)//2(平均の小数点以下切捨)としてP[m] < T ⇒ lb = m,T <= P[m] ⇒ ub = mと解の存在範囲を更新します。lb+1 == ubが成り立つとき、(※)の条件からubこそが「ある値T以上の最初の人のインデックス」であることが分かります。
例として下記の入力が与えられたとき、身長がh_min=3以上の最初の人のインデックスを求めます。
N = 12
H = {1, 2, 2, 4, 4, 5, 6, 6, 7, 7, 7, 10}
h_min=3, h_max=6
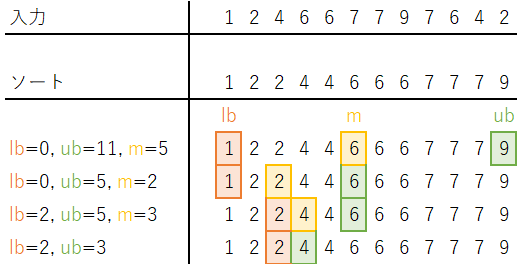
P[0]=1 < T=3であることを確認した上で、lb=0, ub=len(P)=12で初期化します。※配列中にT以上の値がない場合はPの要素数(=12)を返します。m = (lb+ub)//2=(0+11)//2=5となります。P[m]=P[5]=6 >= T=3なのでub = m=5に更新します。m = (lb+ub)//2=(0+5)//2=2となります。P[m]=P[2]=2 < T=3なのでlb = m=2に更新します。m = (lb+ub)//2=(2+5)//2=3となります。P[m]=P[3]=4 >= T=3なのでub = m=3に更新します。lb+1 == ubが成り立ち、「身長がh_min=3以上の最初の人のインデックス」はub=3であることが分かります。
処理の流れが分かったところで、実装をしてみます。
Python:Level2実装例
"""
ソートして二分探索
"""
import bisect
N, Q = map(int, input().split(" "))
P = []
for i in range(N):
h = int(input())
P.append(h)
# O( N*logN )
P.sort()
# O( Q*logN )
for i in range(Q):
h_min, h_max = map(int, input().split())
count = 0
lower = bisect.bisect_left(P, h_min)
upper = bisect.bisect_left(P, h_max + 1)
print(upper - lower)
標準ライブラリを使っている二分探索部分を書き下すとこうなります。
"""
二分探索
"""
def bisect_left(array, target):
if target <= array[0]:
return 0
lb = 0
ub = len(array)
while lb + 1 < ub:
m = (lb + ub) // 2
if target <= array[m]:
ub = m
else:
lb = m
return ub
予めソートする手間はかかるものの、1回ソートしておくだけで、Q回のクエリ処理にかかる時間を大幅に短縮することが出来ます。事前にN人の身長をソートする計算量がO(NlogN)、Q個のクエリそれぞれに対して、二部探索を行う計算量がO(QlogN)で、合計の計算量はO(NlogN) + O(QlogN)になります。
Level3
Level3では制約を更に10倍にした問題を考えます。
制約(Level3)
1 <= N <= 100,000 = 10**5 1 <= Q <= 100,000 = 10**5 1 <= h_i <= 100,000 = 10**5 1 <= h_min_j <= h_max_j <= 100,000 = 10**5
Level2でも高速に検索できてはいますが、まだ無駄な部分があります。1回のクエリを処理するときに2回の二分探索を実行し、前後の境界となる人を探す作業をしています。今回の問題設定では具体的な人を特定する必要はなく、人数だけに着目すれば十分です。情報の持ち方を変えて、各身長ごとに何人いるかを持ってみましょう。
人数だけを配列に持った場合、クエリに対する処理は「下限から上限までの各身長ごとの人数の和」として表現することができます。ここでも注意が必要ですが、クエリごとに下限から上限までを足していったのでは、O(QH)の計算量になり、身長の幅が大きい場合に改善がされません。
情報の持ち方を更に一工夫して、身長i以下の合計人数をi番目の要素として持つような配列を考えましょう。これはO(N+H)で準備できます。Level2と同じ具体例を使って説明します。 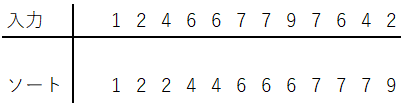 初めに身長の値域分の配列を確保しておき、各人の身長を読み込んだら、対応する値を+1します。この処理は加算N回で
初めに身長の値域分の配列を確保しておき、各人の身長を読み込んだら、対応する値を+1します。この処理は加算N回でO(N)です。次にP[i] = P[i] + P[i-1]としてP[i]が身長i以下の人数を表すようにデータを持ちます。この処理は身長の上限まで足す必要があるため、加算H_MAX回が必要でO(H_MAX)です。 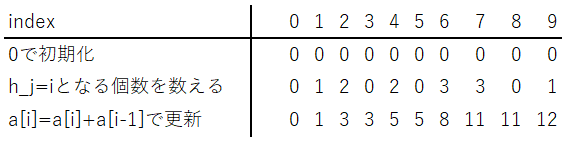
この配列上で、上限と下限の引き算を行うことで、範囲に含まれる人数を答えることが可能です。事前に人数を足して持っておくことで、クエリに対しては1回の引き算(O(1))でレスポンスする事ができます。この手法を累積和といいます。
Level3のポイントを考えてみましょう。
- 身長情報の持ち方を変える
- 毎回の探索さえ必要ない
- 引き算1回で計算すべし
Python:Level3実装例
"""
累積和
"""
H_MAX = 10**5
N, Q = map(int, input().split(" "))
P = []
lower_count = [0] * (H_MAX + 1) # 身長i以下の人数をlower_count[i]に格納する。
for i in range(N):
h = int(input())
lower_count[h] += 1
# O( H_MAX )
for i in range(H_MAX):
lower_count[i + 1] += lower_count[i]
# O( Q )
for i in range(Q):
h_min, h_max = map(int, input().split())
upper = lower_count[h_max]
lower = lower_count[h_min - 1]
print(upper - lower) # 人数が分かっているので引き算だけで答えがわかる。
計算量は O(N) + O(H) + O(Q)になります。毎回の探索が必要ないため、高速に処理をすることが出来ます。
まとめ
今回のワークショップでは、制約の大きさに合わせてアルゴリズムの改善と考え方を紹介しました。
- データ数が少ないなら、実装が簡単な全探索。
- データ数が多い場合はソートしておいて二分探索。(前処理)
- データ数だけが必要になる場合、データ数だけ数えておいて、引き算する累積和の手法が使える。(データの持ち方を変える)
つい先日も社内slackで「O(N)をO(logN)に改善しました!」という話題が上がっていました。計算量を考えながらアルゴリズムの改善をすることに面白さを感じた方、一緒に働けるのを楽しみにしています!
今後のワークショップのご案内
実際のワークショップでは参加者の皆さんが、Level1で問題を理解して、Level2の実装に取り組むという様子でした。競技プログラミングに慣れている方は、Level2までは瞬殺、Level3にチャレンジしていましたよ。
今後もフォルシアでは、ワークショップの開催を予定しています。エンジニアとしての知見を広げたい方フォルシアのことを知りたい方、ぜひご応募お待ちしております!
ワークショップの日程、お申し込みはこちら
松本健太郎
2016年度新卒入社。大手理化学機器商社のECサイトを担当。




{kind=link}