Fargate for EKSでデータ変換バッチのJobを動かした話
こんにちは。旅行プラットフォーム部エンジニアの小孫です。
昨年のアドベントカレンダーの記事で、来年はk8sを本番環境で利用してアドベントカレンダーで書くぞと決意表明しましたが、なんとか今年中に有言実行できました。弊社の「Masstery」というクラウド型のデータクレンジングサービスのデータ変換のバッチ処理を、Fargate for EKSでk8sのJobとして動かしています。
k8s化に取り組んだ経緯
昨年k8sに触れてみて、本番環境で利用してみたいと考えたものの、私が普段担当しているアプリは自社サービスではなくインフラも弊社持ちではないため、実績がないままいきなりk8sを導入するのは難しい状態でした。
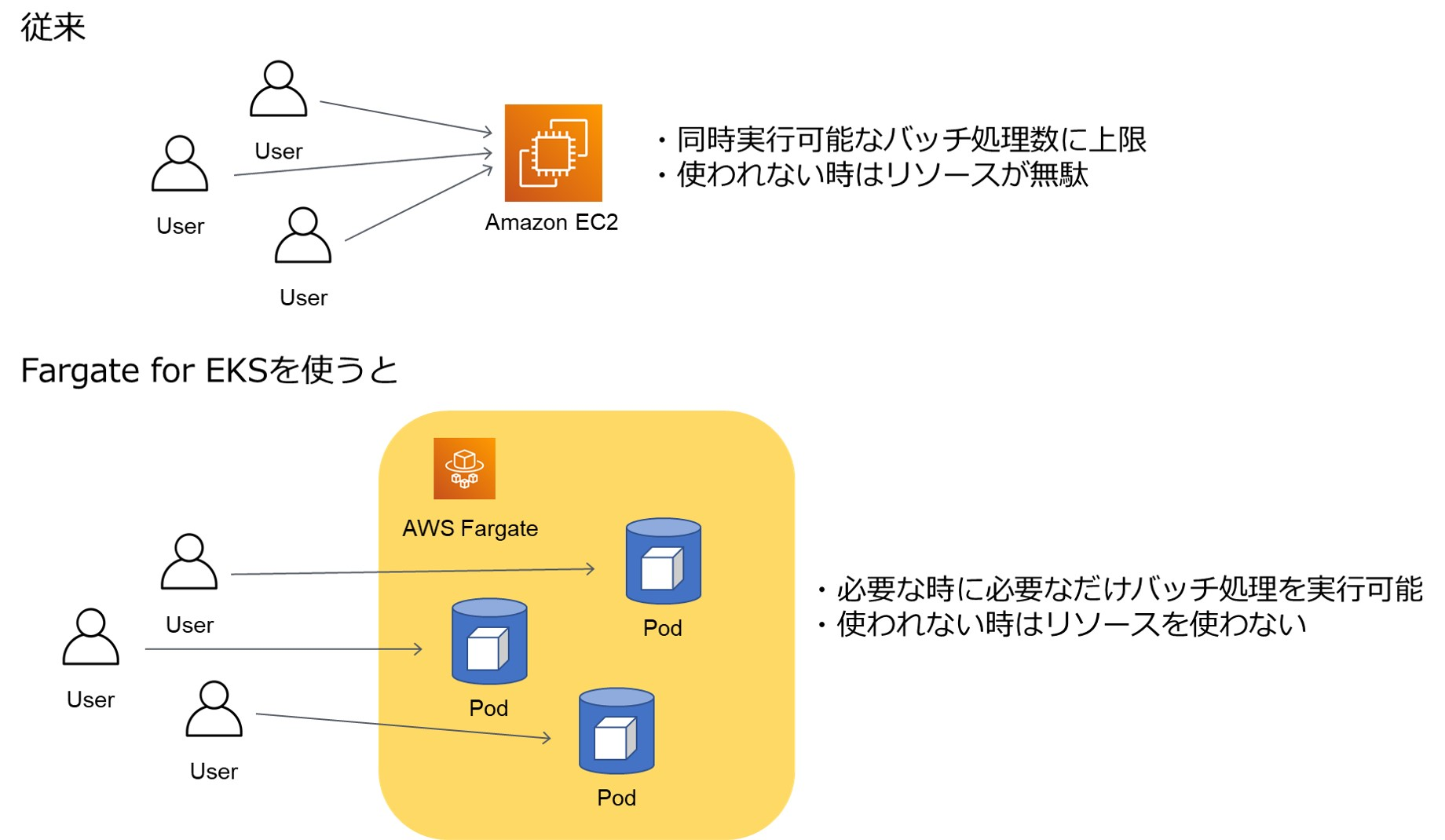
そんなときに、今年ローンチした弊社の新サービス「Masstery」のチームと話をする機会があり、k8sについて話しました。ちょうどMassteryでも将来のユーザー数の増加に備えて、多数のバッチ処理を同時並行で実行できるようにしておく必要がありました。
Massteryのデータ変換バッチでは商品データのフォーマット統一やカテゴリ情報の付与等を行っていますが、バッチ処理が実行されるタイミングはユーザー次第です。そのため通常のサーバーだと必要十分なリソースの調整が難しく、コストパフォーマンスが悪くなってしまいます。
そこで、AWSのFargate for EKSを利用することにしました。FargateはAWSが提供するサーバーレスのコンテナ実行基盤です。通常k8sを利用するには、Podを動かすためのワーカーノード(AWSではEC2)を用意する必要がありますが、Fargateではその必要がなくPod実行時に自動でワーカーノードが用意されます。起動に数分ほどかかるものの、必要な時に必要なだけのリソースを利用できるので、今回のようなバッチ処理にぴったりのサービスです。
k8s化にあたって行ったこと
バッチ処理をFargate for EKSで動かすにあたって、大きく分けて以下の4つの対応を行いました。
- コンテナイメージの作成
- マニフェストやkubectlをラップしたスクリプトの作成
- EKSクラスターの構築
- 実際に動かしてみての課題の対応
一般的にk8sクラスターの構築はインフラエンジニアだけが担当することが多いと思いますが、弊社ではアプリエンジニアとインフラエンジニアの垣根が低く、今回の私のようにアプリエンジニアであっても興味があればインフラ寄りのタスクを担当することがあります。
k8sについては昨年から本を読んだり遊びで動かしたりして、ある程度の予備知識はありましたが、今年CKADの合格を目指して勉強したおかげで、実践的な知識を得ることができました。AWSの知識と経験が浅くEKSクラスターの構築では苦労しましたが、インフラエンジニアと協力し、社内で一足早くk8sを商用利用したアプリの担当者にもアドバイスをもらいながら構築できました。
ここからは、k8s化の過程で工夫したことや困ったことをいくつか紹介します。
コンテナイメージの軽量化
バッチ処理をk8sで動かすにあたって、まずはコンテナイメージの軽量化から始めました。こちらの記事にもあるように、Fargateではイメージのキャッシュが使えず毎回ECRからイメージをプルするため、イメージサイズがPodの起動時間に大きく影響します。
バッチ処理ではPythonイメージを使っていますが、こちらの記事を参考に、pipでインストールしたライブラリをマルチステージビルドで実行用のコンテナにCOPYするようDockerfileを変更しました。これによりビルド時のみ必要で実行時には不要なファイルを省くことができ、イメージサイズを減らせました。Pythonのマルチステージビルドは他にも方法があるようですが、今のところこの方法で問題なく動いています。
# ビルド用コンテナ FROM python:3.x-buster as build-stage WORKDIR /tmp COPY requirements.txt /tmp RUN pip3 install -r requirements.txt # 実行用コンテナ FROM python:3.x-slim-buster # ビルド用のコンテナから、pipでインストールしたライブラリをコピー COPY --from=build-stage /usr/local/lib/python3.x/site-packages /usr/local/lib/python3.x/site-packages COPY --from=build-stage /usr/local/bin /usr/local/bin
また、Docker公式のベストプラクティスにも書かれていますが、apt-getでのライブラリのインストール後に、パッケージキャッシュをクリーンにし/var/lib/apt/listsを削除することでイメージサイズを減らしました。(apt-get updateの実行により、パッケージのinstall時に参照するインデックスファイルがダウンロードされるディレクトリが/var/lib/apt/listsです。)
# 必要なライブラリをインストール後、キャッシュを削除 RUN apt-get update \ && apt-get install -y hoge fuga piyo\ && apt-get clean \ && rm -rf /var/lib/apt/lists/*
その他、不要にインストールしていたモジュールを削除することでコンテナイメージを軽量化し、運用上支障のないPod起動時間に短縮できました。
EFSの利用で実行時間が延びた原因
コンテナを利用する際には永続データをどう扱うかを考える必要があります。
当初はバッチ処理の変換前後のデータや、データ変換に必要なファイルはS3に置いて、バッチ処理の前後にPodからS3にアクセスする予定でした。ただ、Fargateの一時ボリュームは20GBであり、データ変換で用いる機械学習モデルや自然言語処理の辞書まで持つには心許ない容量です。
しかしちょうど今年8月にFargate for EKSでもEFSをサポートするという朗報があり、早速Fargate for EKSでEFSを利用することにしました。FargateのPodにEFSをマウントすることで、バッチ処理自体のロジックを変更することなく永続データを扱えるようになり、容量も気にせずに済むようになりました。
ところが実際にFargateでバッチ処理を実行してみると、なぜか特定の処理に通常の10倍ほど時間がかかるようになってしまいました。Kubernetesダッシュボードで確認するとCPUやメモリはボトルネックとなっておらず、I/Oの問題かなと思いつつもなかなか原因がわかりませんでした。
試しにEFSに置いているあるファイルをPod起動時にコンテナ内にコピーして、バッチ処理ではそちらを参照するように変更してみると、処理時間が通常になりました。このファイルに対して頻繁にI/Oが発生するロジックになっていたため、EBSのようなローカルストレージよりレイテンシが大きいEFSでは処理に時間がかかってしまっていたようでした。
Fargate for EKSはEFSのサポートにより利用の幅が大きく広がりましたが、EFSの利用にあたっては今回のように頻繁にI/Oが発生しないようなロジックの工夫が必要だということもわかりました。
また今回は利用しなかったS3ですが、整合性が強力になった(書き込みの直後に読み取りができるようになった)ことが先日発表されたので、ストレージの選択肢の一つとして今後利用できる場面がさらに増えそうです。
kubectl waitコマンドでPodの監視
監視については、以前からPrometheusを利用してリソースやログの監視を行っていました。バッチのログはPodにマウントしているEFSに書き出すようになっているので、grok_exporterを動かしているEC2でログを監視するようにしました。
また、Job実行後にPodのステータスがReadyになったかどうかはPrometheusでは監視できなかったので、Job実行時にkubectl waitコマンドを実行して、その結果をJob実行をキックしているWebアプリのログに出力するようにしました。このログもgrok_exporterで監視しているので、何らかの理由でPodが起動できなければ検知されるようになっています。
さらにJobやPodの異常終了についても、Job実行時にkubectl waitコマンドでJobの正常終了のタイムアウトを設定することで監視しています。
なお、kubectl waitコマンドはExperimental(実験的)な機能です。たしかに、タイムアウトを2時間に設定したのに結果が返ってくるのが2時間半後ということがありました。現時点では使える場面が限られますが、時間に厳密さを求めないのであれば使いやすい機能だと思います。今回はこれで十分でしたが、ワークフロー処理のように状態変化を即座に検知する必要がある場合には、社内でモジュールを開発して対応しています。
完了したJobの削除
バッチ処理ではk8sのJobリソースを使っています。k8sのJobとそれに紐づくPodは、 完了後も自動で削除されずに残り続ける仕様です。
これは完了後のPodでログを確認できるようにするためですが、Podが残り続けるとFargateの課金の対象となってしまいます。完了後のリソースを一定時間後に削除するTTL controllerという仕組みも存在しますが、現時点ではEKSでは利用できないものです。
そこでこちらの記事を参考に、EKS管理用のEC2からcronで定期的に完了したJobを削除するようにしました。
$ kubectl delete job $(kubectl get job -o=jsonpath='{.items[?(@.status.succeeded==1)].metadata.name}')
また、異常終了したJobについては調査を行う時間を考えて、1日に1回、開始後1日以上経っているJobの削除を行うようにしました。
$ kubectl delete job $(kubectl get jobs | awk '$4 ~ /d/' | awk '{print $1}')`
最後に
一年前は本当にk8sを本番運用まで持っていけるのか?というのが正直な気持ちでしたが、一つずつステップを踏んでいくことで実現できました。開発環境でのコンテナ利用にとどまらず、本番環境でk8sを利用することで、アプリ運用の可能性が大きく広がることを実感しました。来年も新しい技術に挑戦していきたいです!
小孫 一浩
旅行プラットフォーム部所属。2017年新卒入社。
アドベントカレンダー4年目にしてようやく技術っぽい記事を書けました。
おいでやすこがの今後が気になっています。



